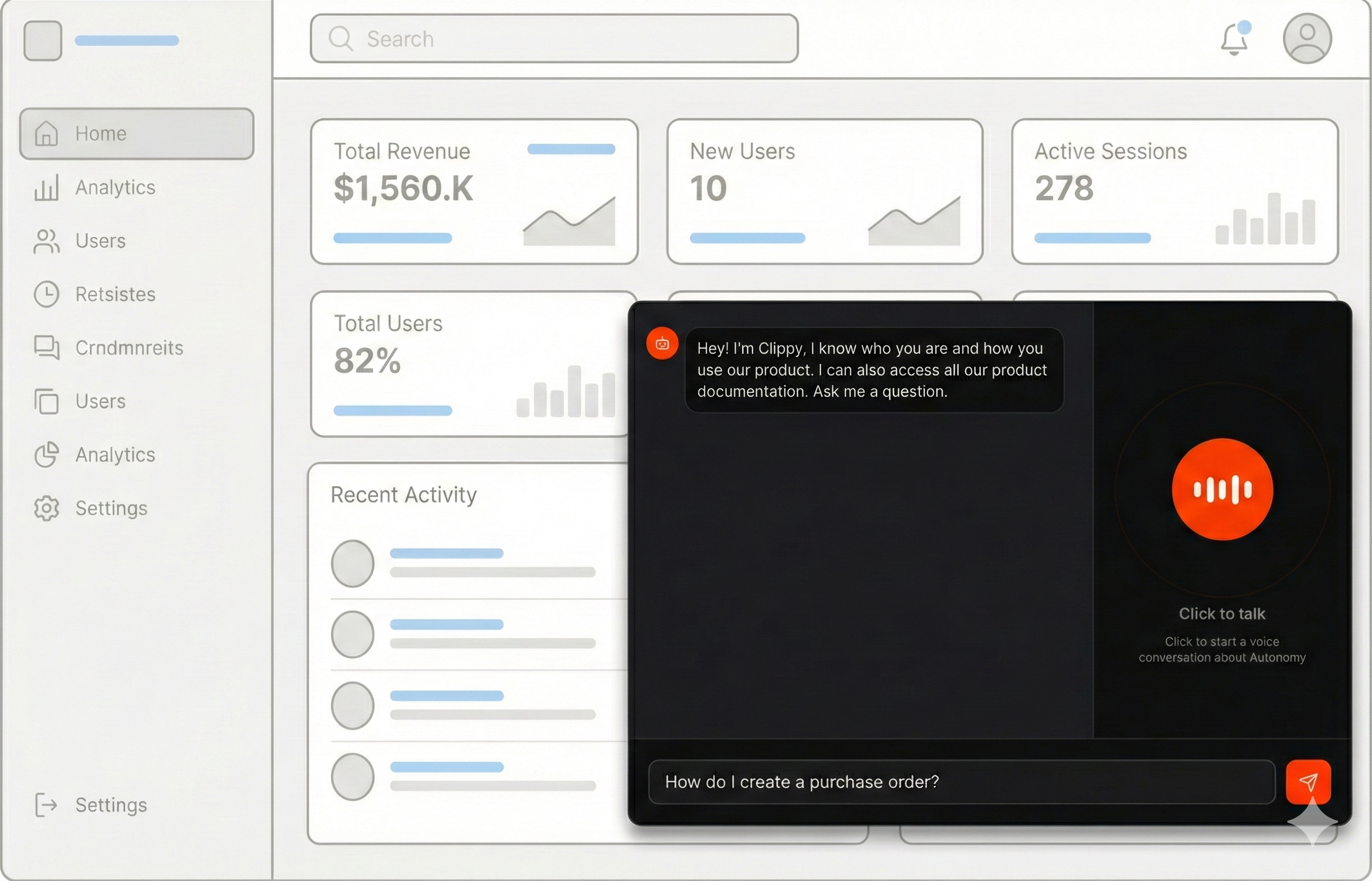
 This lets us tailor the experience of each visitor. Agents receive custom
instructions that adapt responses for different audiences, such as developers,
analysts, investors, or first-time visitors.
***
## Make your docs come alive!
In the next few minutes you can launch an app and apis for agents that:
* Speak answers drawn from your docs.
* Search your docs using vector embeddings.
* Respond fast using a two-agent delegation pattern.
* Reload docs periodically to stay current.
* Work through voice and text.
* Trigger your product's APIs to take actions.
This lets us tailor the experience of each visitor. Agents receive custom
instructions that adapt responses for different audiences, such as developers,
analysts, investors, or first-time visitors.
***
## Make your docs come alive!
In the next few minutes you can launch an app and apis for agents that:
* Speak answers drawn from your docs.
* Search your docs using vector embeddings.
* Respond fast using a two-agent delegation pattern.
* Reload docs periodically to stay current.
* Work through voice and text.
* Trigger your product's APIs to take actions.