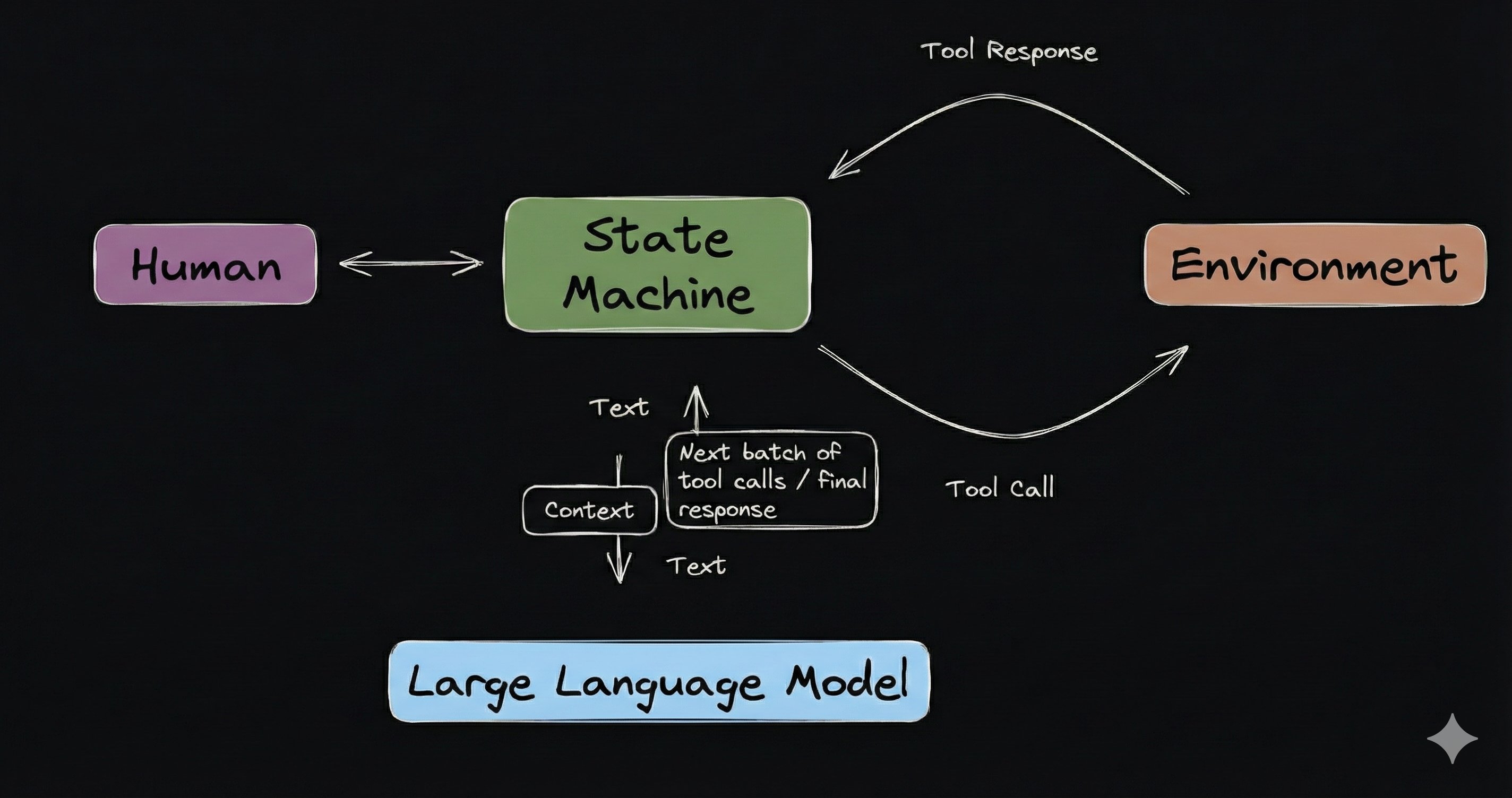
from autonomy import Agent, FilesystemTools, HttpServer, McpClient, McpTool, Model, Node, NodeDep
from fastapi import FastAPI
from asyncio import create_task
app = FastAPI()
@app.post("/research")
async def research_legal_case(request: dict, node: NodeDep):
"""
Research a legal case by breaking it into research questions and investigating each question.
"""
case_description = request.get("case_description", "")
if not case_description:
return {"error": "No case description provided"}
# Start the lead researcher agent with parallel research subagents
lead_researcher = await Agent.start(
node=node,
name=f"lead_researcher_{id(case_description)}",
instructions="""
You are a lead legal researcher coordinating a research team.
Your job is to:
1. Analyze the case and break it down into specific, focused research questions
2. Save your research plan to a file for reference
3. Use delegate_to_subagents_parallel to assign each question to research assistant subagents
4. As findings come in, save them to organized files
5. Compile all research findings into a comprehensive legal research memo and save it
You have filesystem access to:
- Save research plans and notes
- Organize findings by topic or question
- Draft the research memo incrementally
- Create a final polished memo
Focus on actionable research questions such as:
- Relevant statutes and their interpretations
- Applicable case law and precedents
- Jurisdictional issues
- Elements that must be proven
- Defenses that may apply
- Recent developments in this area of law
When you have identified the research questions, use the delegate_to_subagents_parallel tool
to have all questions researched simultaneously by passing the role "research_assistant"
and a list of research questions as tasks.
Use the filesystem to stay organized throughout the research process.""",
model=Model("claude-sonnet-4-v1"),
tools=[FilesystemTools(visibility="conversation")],
subagents={
"research_assistant": {
"instructions": """
You are a legal research assistant specializing in thorough legal research.
When given a research question:
1. Use the brave_web_search tool to find relevant legal authorities, statutes, and case law
2. Use filesystem tools to save your research notes and organize your findings
3. Analyze the sources to extract key legal principles and holdings
4. Synthesize your findings into a clear, well-organized response
5. Cite specific authorities with case names, statutory citations, or source URLs
You have filesystem access for organizing your research work. Use this to:
- Save important case summaries and statutory findings as you find them
- Keep notes on sources you've reviewed
- Draft and refine your response before returning it
- Maintain organized research files
Focus on finding:
- Controlling statutes and regulations
- Binding precedent from relevant jurisdictions
- Persuasive authority from other jurisdictions
- Recent cases that interpret or apply relevant law
Prefer authoritative legal sources:
- Court opinions from official reporters or government sites (.gov)
- Legislative websites for statutory text
- Law school websites (.edu) for scholarly analysis
- Legal research databases (Justia, FindLaw, etc.)
Format your response as:
Research Question: [Restate the question]
Key Findings: [Summarize the most important discoveries]
Relevant Authorities: [List statutes, cases, and other sources with citations]
Analysis: [Explain how these authorities apply to the question]
Recommendations: [Suggest next steps or further research needed]""",
"model": Model("claude-sonnet-4-v1"),
"auto_start": False,
"tools": [
McpTool("brave_search", "brave_web_search"),
FilesystemTools(visibility="conversation")
],
"max_execution_time": 120
}
}
)
try:
# Send the case to the lead researcher
response = await lead_researcher.send(
f"""
Please conduct comprehensive legal research on this case:
{case_description}
Break this down into focused research questions, assign each question to a research assistant
in parallel, and compile the findings into a detailed legal research memo that includes:
- Executive summary of the case
- Research questions identified
- Findings for each question with citations
- Overall legal analysis and recommendations""",
timeout=3600
)
# Extract the final response
research_memo = response[-1].content.text if response else "No response"
return {"research_memo": research_memo}
except Exception as e:
return {"error": str(e)}
finally:
# Clean up the lead researcher agent
create_task(Agent.stop(node, lead_researcher.name))
Node.start(
http_server=HttpServer(app=app),
mcp_clients=[
McpClient(name="brave_search", address="http://localhost:8001/sse")
]
)